
C++ Meets Python: Integrating LLMs into Your Application
You want to integrate the latest large language model (LLM) into your application, but you face a dilemma: your code base is in C++ while machine learning (ML) frameworks predominantly use Python. We faced such a challenge recently and here is what we learned.
First, a little background. Our application, CarChat, is a ML-powered voice assistant to help drivers interact with their vehicle. There are three ways to begin a conversation:
- The driver initiates a conversation to get answers to vehicle related questions like “How much further can I drive?” or “Where can I get some food?”
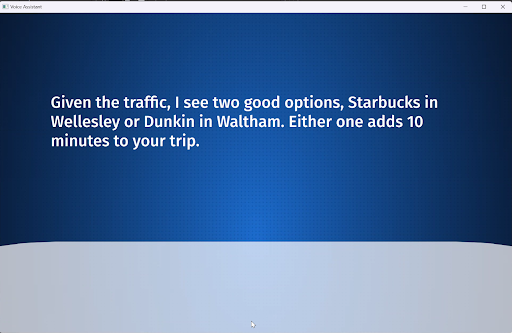
- The voice assistant starts a conversation in response to vehicle status like changes in speed, fuel level, etc. This would be something like “You are low on fuel. The nearest gas station is 3 miles away” or “you are speeding, please slow down.”
- The voice assistant initiates a conversation in response to driver status monitored by camera. It might say “You appear to be falling asleep, pull over and take a break as soon as possible.”
As is often typical, one big challenge was which tech stack to choose? On one hand, we could use C++ which is a mature industrial strength language with true multi-threading. Furthermore, we could then utilize Qt and QML for a rich framework for coding and visualization.
On the other hand, Python is the language of choice for LLM investigations. There is support for rich featured frameworks like LangChain that lets you build LLMs by chaining interoperable components together. A key feature is that LangChain provides a layer of abstraction so we could readily swap out our initial cloud based GPT-4o model for a local model like Llama 3.2. We also had the need for data validation and management libraries like Pydantic.
Since we really needed both C++ and Python, our first thought was a mixed language approach using bindings, e.g., PyBind or Boost.Python, to have Python call C++ or C++ call Python. Unfortunately, there are issues with this approach starting with Python’s Global Interpreter Lock (GIL) which can prevent true parallel execution of Python code.
Even though C++ threads can run concurrently, Python’s GIL needs to be explicitly managed when calling C++ code from Python. Other issues arise around threads and memory management between the languages, possible deadlocks, memory leaks, crashes if Python garbage collection conflicts with C++ smart pointers, and even linker issues.
Solution: Keep Both Python and C++ in a Pure Form
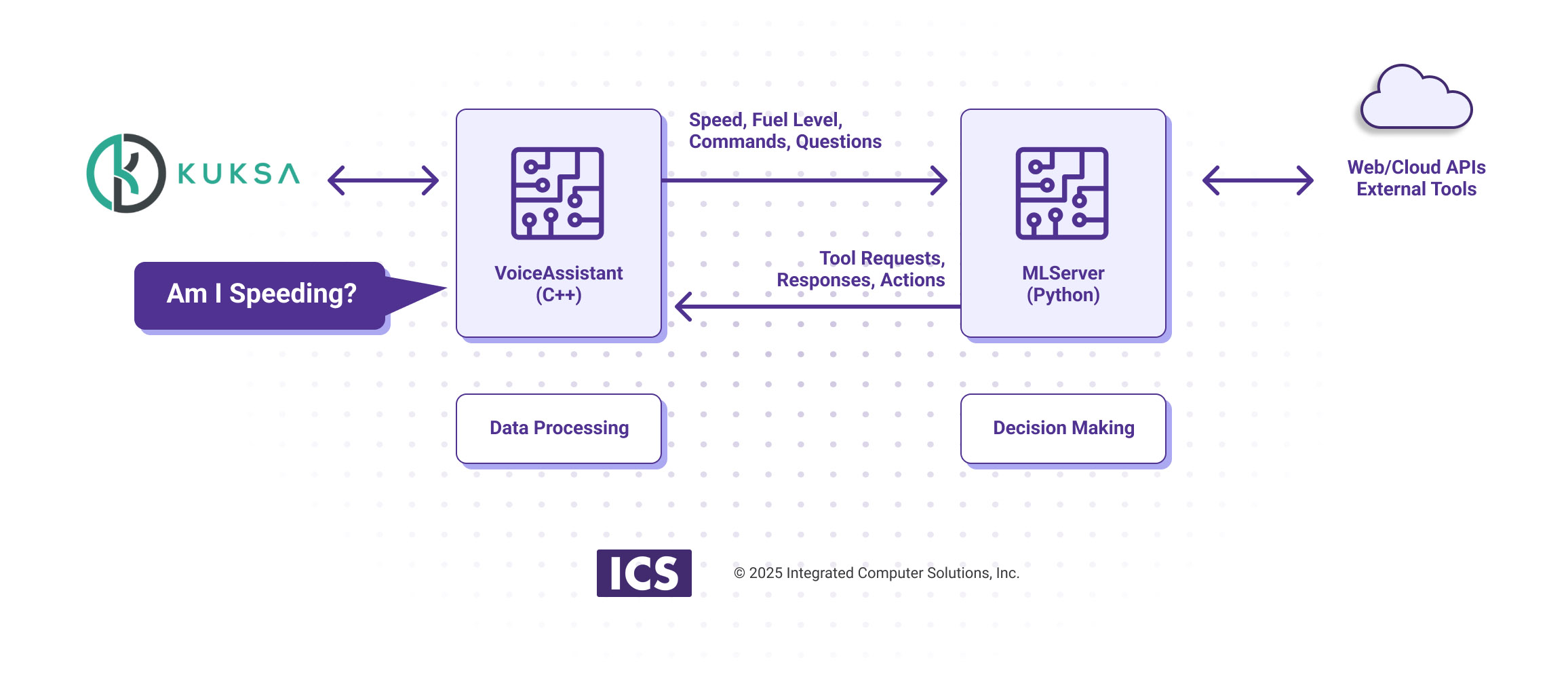
We concluded that even if we could ultimately overcome these issues, that is not where we wanted to spend our development time. Thus our solution was to keep both Python and C++ in a pure form using a client server model as follows:
- Our C++ frontend named VoiceAssistant is the eyes and ears as well as the workhorse. It keeps track of vehicle state, e.g., fuel level, speed, etc, and issues commands, e.g., turn up the heat, by interacting with a Kuksa data broker. Other components include voice-to-text and text-to-voice to converse with the driver. VoiceAssistant uses QML, Qt’s visualization language, to create a pleasing user graphical experience.
- On the backend is MLServer that provides the brains of CarChat. This Python based LLM decides which action to take based on text based input from voice-to-text relayed via VoiceAssistant , e.g. “how much gas do I have left” or vehicle state initiated text status, e.g., “fuel level is 50%”.
With this architecture, the Python MLServer decides which tools to call, but the actual tools called are C++ methods in VoiceAssistant.
To describe our setup further, I’ll start with Python where we used a FastAPI server with a very simple API, e.g., query and response. Except for debugging, it boils down to one API command.
http://{server}/chain/invokeThe input is a POST request which is a natural language string that will be processed by the LLM. Examples might be “Speed is 40”, “Fuel level is 10”, “Speed limit is 30”. On the Python side, these will be included as part of the prompt to the LLM. The C++ side will receive back a JSON response that might be a text answer like “You are 10 miles over the speed limit, please show down” or it could be a request for a tool call like “getSpeed()”. In the former case, the interaction is complete while in the latter case, there will be at least one more iteration as the C++ side reports the speed and the Python server decides what to do.
All this lead up brings us to the main point of the article which is how to safely call C++ methods from Python. It's fairly simple with a block of code on the Python side and a related block on the C++ side for each tool that needs to be called. Starting with Python, a typical tool definition might look like the following:
from langchain_core.pydantic_v1 import BaseModel, Field
class get_speed_value(BaseModel):
"""Return the vehicle speed value."""
rpm: int = Field( description="This is the current vehicle speed value.")Some things to note:
We use Pydantic to make sure the input and output is structured correctly.
“””Return the vehicle speed value.””” is essentially a prompt. The LLM will decide when and if this method should be called based on user input.
For clarity’s sake, we have a separate Python file for each tool, but they could be combined.
Now, onto the partner code on the C++ side VoiceAssistant. First, the function must be defined and registered.
QString AgentMgr::getSpeedValue(){
return QString::number(base->kuksaManager()->getSpeed());
}This defines the method. The return value is a string because that is how we communicate with the LLM. Beyond the scope of this article is the kuksaManager which gets and sets values via Kuksa message service.
void AgentMgr::initialize() {
// lots of other stuff
functionMap["get_speed_value"] = makeFunction(&getSpeedValue);
}This registration is essentially a hash on the Python class name with address of C++ function.
Next we parse the JSON response from MLServer to see if any tools need to be called. In the snippet below, we go about the business of actually calling the tools and creating a response.
AgentMgr::onQueryResponse(responseData) {
ToolCallList *toolsToCall = parse(responseData);
for( ToolCall *tool : toolsToCall) {
QString name = tool->name;
QString id = tool->id;
Args args = tool->args;
QString result = functionMap[name]->call(args);
// append results to conversationalModel
m_model->append(name, id, result);
}
}After a request is made to MLServer, we parse the response to see if there are any C++ methods to call. If there are, we make the call(s) and then append the text results to the conversation and send it back to MLServer in a feedback loop that ends after a few iterations.
To recap, there are three pieces of code to write in C++ and one in Python. They are:
- Python function definition with Prompt language when to call.
- C++ function definition that corresponds to the Python function
- Save both function names in C++ in some sort of hash table structure
- Make the API call and parse the results. If there is a function call request, make it.
Recall that our initial motivation was to get true C++ multithreading while avoiding mixed language issue programs like memory, thread and link issues. By adopting the described architecture, we now have the option to put all the Python code on a separate server and have the ML brain call a local LLM instead of a cloud based LLM given sufficient hardware and the appropriate model.
On the downside, the biggest issue is there are two pieces of software to start, run, and deploy. In practice, this is not a huge drawback, but simply more work to be done. Potential problems like latency are minimal since we are interacting with VoiceAssistant at a human pace and only have to go as fast as a person can think and talk.
Key Takeaway: Bridging C++ and Python for Optimal LLM Integration
We faced a challenge in that C++/Qt/QML provide an industrial strength base for applications in terms of UI, robustness, etc -- but Python frameworks are superior for flexibility integrating LLMs. Trying to combine Python and C++ into a single application, even when taking advantage of helper libraries, can lead to problems late in a project. By adopting a client server mode, we avoid those issues with minimal downside.
If you’re facing a similar challenge of integrating LLMs into your C++ application, our team is here to help. We specialize in creating seamless bridges between C++ and Python, ensuring your application benefits from the best of both worlds. Reach out today, and let’s tackle this challenge together!